The antigen binding properties of antibodies are determined by the sequences of their corresponding B cell receptors (BCRs). These BCR sequences are created in “draft” form by VDJ recombination, which randomly selects and trims the ends of V, D, and J genes, then joins them together with additional random nucleotides. If they pass initial screening and bind an antigen, these sequences then undergo an evolutionary process of mutation and selection, “revising” the BCR to improve binding to its cognate antigen.
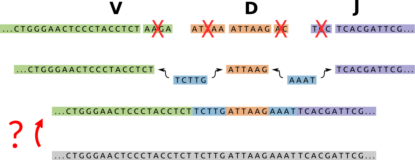 Our first paper on BCRs concerned natural selection as part of the “revision” process, and when Duncan joined the group we got to work on the “drafting” part.
Specifically, the first step was to work on the annotation problem: given a BCR sequence, which nucleotides came from which genes or non-templated insertions?
We recently posted a paper on arXiv describing our approach.
Like previous work, we use a hidden Markov model (HMM) for this problem, but different from previous work, our emission and transition probabilities are parameter-rich categorical distributions, which are inferred “on the fly” for each data set.
We are motivated to do so by noting that these distributions deviate significantly, and reproducibly, from standard parametric distributions.
In our simulations we see significantly better performance using these parameter-rich distributions.
Next we will use the same framework to cluster BCR sequences by rearrangement event.
Our first paper on BCRs concerned natural selection as part of the “revision” process, and when Duncan joined the group we got to work on the “drafting” part.
Specifically, the first step was to work on the annotation problem: given a BCR sequence, which nucleotides came from which genes or non-templated insertions?
We recently posted a paper on arXiv describing our approach.
Like previous work, we use a hidden Markov model (HMM) for this problem, but different from previous work, our emission and transition probabilities are parameter-rich categorical distributions, which are inferred “on the fly” for each data set.
We are motivated to do so by noting that these distributions deviate significantly, and reproducibly, from standard parametric distributions.
In our simulations we see significantly better performance using these parameter-rich distributions.
Next we will use the same framework to cluster BCR sequences by rearrangement event.