The project
Bayesian phylogenetic (evolutionary tree) inference is important for genomic epidemiology and for our understanding of evolution. Trees, along with associated information, are complicated objects of inference, with intertwined discrete (tree structure) and continuous (dates, rates) structure. Random-walk Markov Chain Monte Carlo, implemented in packages such as BEAST (~20,000 citations) and MrBayes (>70,000 citations), is currently the only widely-applied inference technique.
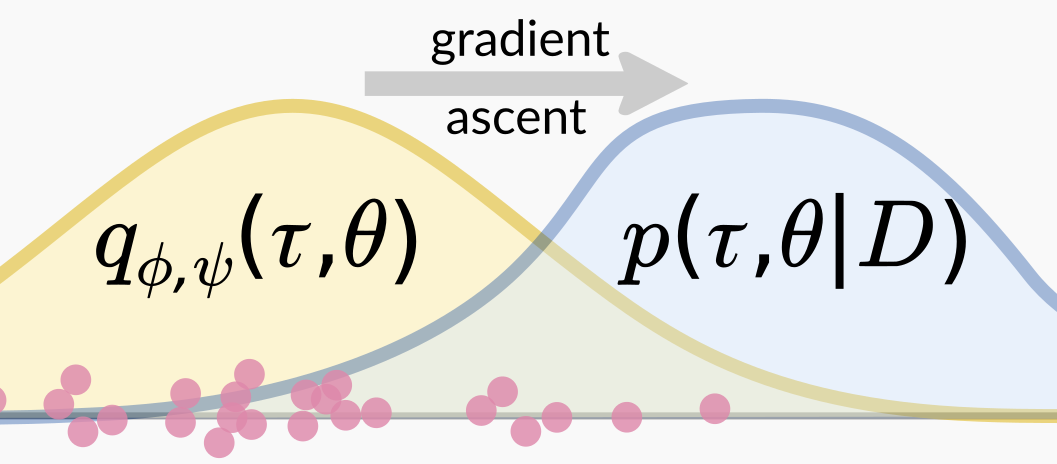
We have recently developed a rich means of parameterizing tree distributions with a fixed parameter set. This renders them accessible to more modern inference techniques, such as variational Bayes. We have developed a proof-of-concept application of phylogenetic variational Bayes using modern general-purpose gradient estimators. Our collaborative group also has preliminary integrations with both PyTorch and TensorFlow.
To achieve the promise of variational Bayes phylogenetics, we will develop:
- structure learning methods that will infer the discrete aspect of our variational approximation
- fitting methods that leverage the special structure of our variational phylogenetic models
- a modeling framework that integrates with PyTorch, enabling rich models that leverage covariates such as travel history.
This will be a collaborative project with
- Marc Suchard, a leading statistician especially known for his work in “phylodynamics:” the intersection of phylogenetics, immunology, and epidemiology
- Mathieu Fourment, who has led the development of fixed-tree variational inference for time-tree models
- Cheng Zhang (张成), who has led the development of flexible-tree variational inference.
These other groups will focus more on the 3rd aspect, whereas the Fred Hutch group will focus more on the 1st and 2nd aspect.
We are implementing these algorithms in our Python-interface C++17 library.
Environment
The position will come with a competitive postdoc-level salary with great benefits for two years, with the ability to extend if things are going well. The environment is lively yet casual, with a strong emphasis on collaborative work. The Center is housed in a lovely campus on Lake Union a short walk from downtown, and a slightly longer walk from the University of Washington. The Matsen group is in the newly-remodeled Steam Plant building overlooking the lake. Powerful computing resources and helpful IT staff await. Ideally you’d want to be on campus but long-term remote work is possible from these states: Alabama, Alaska, Arizona, California, Colorado, Hawaii, Idaho, Maryland, Minnesota, Montana, New York, Ohio, Oregon, South Carolina, and Texas.
{kind=link}
We believe that science is for everyone. We have had researchers with a variety of backgrounds, including Latinx, Black, Asian, and Middle Eastern. We have had women, men, gay, and straight, and we welcome people of all sexual orientations and gender identities. We have had successful high schoolers, postdocs, people who were the first in their family to attend college, and one who had decided that college wasn’t for them. We have had researchers with backgrounds in biology, physics, statistics, math, and computer science.
We acknowledge the historical and present barriers for underrepresented groups, and work to increase diversity, equity and inclusion in computational biology. Members of underrepresented groups are especially encouraged to apply.
Please read our expectations of group members. By applying for this position, I expect that you will fulfill these expectations. I enthusiastically solicit feedback on these expectations or requests for clarification.
You can find out more about our group by visiting:
Qualifications
This position requires a PhD in statistics, computer science, biology, or another relevant field.
Essential skills
We are looking for someone who has:
- experience doing methods development for a challenging Bayesian estimation problem
- clear ability to perform independent research
- the ability to work and collaborate with a team.
Additional helpful skills
Ideally the candidate would have:
- experience with PyTorch or TensorFlow
- experience with C++, and with modern C++ idioms
- experience with a modern git-based workflow
- experience with Docker and continuous integration
- experience developing in a Linux environment
Applying
If you are interested in this position, please submit the following materials:
- Two representative publications.
- A CV summarizing your education and work experience so far.
- The names and email addresses of three references.
- A code sample showing work that you are proud of. This has to be nontrivial, but doesn’t have to be long. Ideally it would be publicly accessible, e.g. on GitHub, but if that’s not possible an emailed attachment is fine too.
Please send these materials to: if you’re interested.